Count all distinct substrings
Given a string $s$, determine the number of distinct substrings that it contains.
Example
ABABA # given string
A # all distinct substrings
B
AB
BA
ABA
BAB
ABAB
BABA
ABABA
Brute force solution
A straightforward solution would be to compute all substrings, store them in a set, and return the size of the set. A hash based set would be more efficient than a binary search based set. In Python this can be written in a single line.
len(set(s[i:j] for j in range(len(s) for i in range(j))))
The complexity of this approach is $O(n^3)$, where $n$ is the length of $s$. This might be too large for some problems. Let’s consider different approaches.
Polynomial hashing
A simple and elegant solution, consists in the use of polynomial hashing. The idea of computing the hash for some string $s$ is that for some integer Q and a prime number P, we read $s$ as a number written in base Q, and keep only the modulo with P, in order to avoid to deal with huge numbers.
The use of modulo might generate some collisions in the hash value, but by choosing a large enough P, the probability of this even can be made arbitrarily small.
Let’s see an example. For the ease of presentation, we map A to 0, B to 1, etc, and use Q=10, and P arbitrarily large.
ABBCAB # given string s
011201 # corresponding hash value (11201 without leading zero)
The hash value can be defined recursively as
- hash(empty string) = 0
- hash(wx) for some string w and character x is $(Q \cdot \textrm{hash}(w) + x) \bmod P$, where we abused notation and used $x$ both for the character and its ASCII code.
This recursion allows us to compute in linear time the hashes of all prefixes of the given string $s$. Once we have this table, we can compute in constant time the hash value of a substring, by simple arithmetic operations. Let’s see this on an example.
A B B C A B # given string s
^0 # hashes of all prefixes
^1
^11
^112
^1120
^11201
A B[B C A]B # specified substring s[i]...s[j]
0 1 1 2 0 # hash value of j-th prefix
0 1 # hash value of (i-1)-th prefix
0 1 0 0 0 # multiplied by $Q^{j-i}$
1 2 0 # the difference is the hash of the substring
This leads to a solution in time $O(n^2)$. Simply pre-compute the hashes of the prefixes. Then for every index pair (i,j), compute the hash of the substring, and store these hash values in a set. Finally return the size of the set.
Sounds simple, right? But do you see a problem with this approach? Well, by the birthday paradox P needs to be really large in order to avoid collisions. In expectation, it needs roughly $\sqrt P$ hash numbers in order to create a collision. Since we have to store $O(n^2)$ numbers, one for each substring, P would need to be in the order of $n^4$. For n=1000, this would make P of the order of $10^{12}$. It should not be a problem, when computing with 64 bit numbers, but I did not managed to find a prime P which would lead to a program, which is both correct and quick enough (avoiding the use of arbitrary precision arithmetics).
Hence we propose a different approach.
Suffix tree
Consider all the suffixes of the given string s.
ABBCAB # given string s
ABBCAB # all suffixes of s
BBCAB
BCAB
CAB
AB
B
Now store all these substrings in a trie, i.e. a prefix tree.
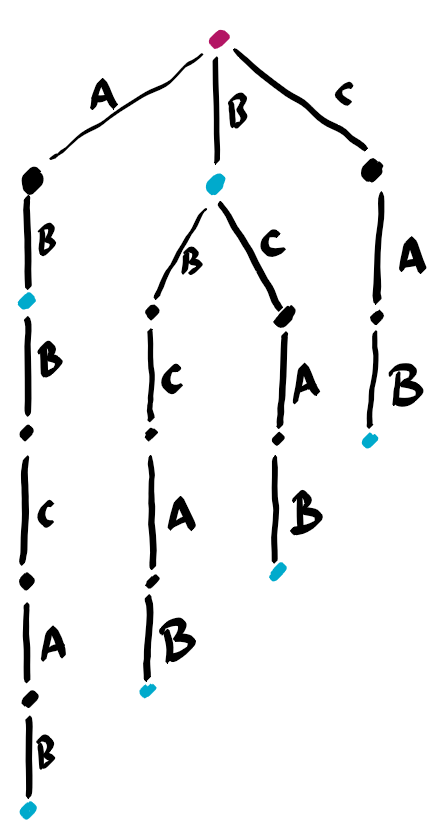
Edges are labeled with letters. For every non root vertex, the letters along the path from the root to that vertex constitute a string. In particular paths from root to leafs are suffixes of s. If we had appended s by a special character $, as it is often done, then there would be a one-to-one correspondence between leafs and suffixes. Without that special character, this is not the case. Therefore we marked in blue the vertices corresponding to suffixes.
The important point is that every substring is a prefix of a suffix, and therefore the number of distinct (non empty) substrings is the number of vertices (excluding the root) in this tree.
The suffix tree can be build in linear time using Ukkonen’s algorithm for example, but the algorithm is not easy to understand. Hence we propose an alternative approach.
Suffix array
A suffix array is a data structure which is closely related to a suffix tree, having about the same purpose. We refer to this excellent note for a more detailed description, and to this excellent webpage for good illustrations in action.
The principle is that we would like to order all suffixes lexicographically. Once we have done this, we are able to answer quickly many queries on the string s, as explained later.
ABBCAB # given string s
AB # sorted suffixes
ABBCAB
B
BBCAB
BCAB
CAB
The key to good performance is to sort them by prefixes of increasing sizes 1, 2, 4, 8, and so on. By sorting, we mean that we associate to every suffix a rank in that order. Below we show the rank, when comparing the prefixes according to the $2^k$ first characters.
k= 0 1 2 3
AB 0 0 0 0
ABBCAB 0 0 1 1
B 1 1 2 2
BBCAB 1 2 3 3
BCAB 1 3 4 4
CAB 2 4 5 5
For practical reasons, instead of working with the rank, we work with pseudo-ranks. The only difference with ranks is that they are not consecutive. The next pseudo-rank after v is not necessarily v+1, but could be any strictly larger integer.
In particular, for k=0, we could just use the ASCII value of the first character, as the pseudo-rank of the suffixes.
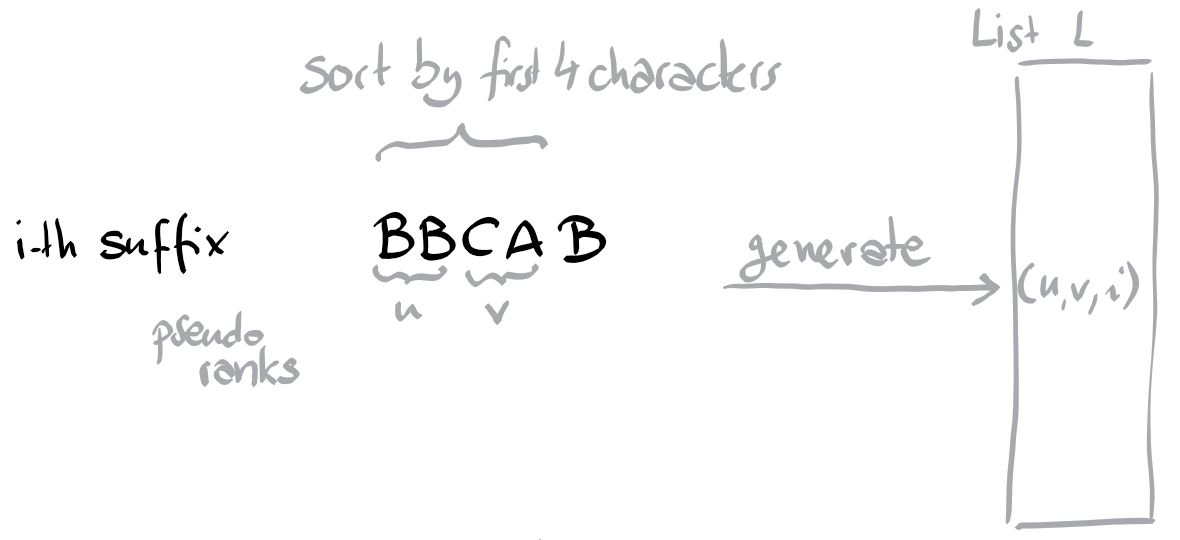
Suppose we want to compute the pseudo rank of the suffix BBCAB of index i according to the first 4 characters. The idea is to create a pair (u,v) such that u is the pseudo rank of the first 2 characters (BB) and v is the pseudo rank of the next 2 characters (CA). And here we can use what we have computed previously. This would constitute a list L of triplets (u,v,i), which we can sort lexicographically. For any consecutive triplets (u,v,i), (u’,v’,j) in L, if (u,v)=(u’,v’) then we know that the j-th suffix needs to receive the same pseudo-rank as the i-th, otherwise it needs to receive a larger pseudo-rank. (Its position in L for example).
In the code below we compute a matrix P such that $P[k][i]$ is the pseudo rank of the i-th suffix according to the $2^k$ first characters. This matrix has dimension $\lceil \log_2 n\rceil \times n$. For all rows, except the first one, we have the property that pseudo-ranks are between 0 and n-1. Since all pseudo-ranks in the last row are distinct, the last row stores the rank of the suffixes. This describes a permutation. For convenience we inverse this permutation and store in suf_sorted[r] the index i of the r-th smallest suffix.
Many implementations keep only the last row of P, and instead of building the whole matrix, only store one row at a time, building one row from the previous one. But informations contained in the matrix are useful for some tasks.
This implementation has time complexity $O(n \log^2 n)$, since we are lazy. Implementing an appropriate bucket sort would shave a logarithmic factor, but it is not clear if in practice it would beat the build-in sort function in performance.
class SuffixArray:
""" by Karp, Miller, Rosenberg 1972
s is the string to analyze.
P[k][i] is the pseudo rank of s[i:i+K] for K = 1<<k
among all strings of length K. Pseudo, because the pseudo rank numbers are
in order but not necessarily consecutive.
Initialization of the data structure has complexity O(n log^2 n).
"""
def __init__(self, s):
self.n = len(s)
if self.n == 1: # special case: single char strings
self.P = [[0]]
self.suf_sorted = [0]
return
self.P = [list(map(ord, s))]
k = 1
length = 1 # length is 2 ** (k - 1)
while length < self.n:
L = [] # prepare L
for i in range(self.n - length):
L.append((self.P[k - 1][i], self.P[k - 1][i + length], i))
for i in range(self.n - length, self.n): # pad with -1
L.append((self.P[k - 1][i], -1, i))
L.sort() # bucket sort would be quicker
self.P.append([0] * self.n) # produce k-th row in P
for i in range(self.n):
if i > 0 and L[i-1][:2] == L[i][:2]: # same as previous
self.P[k][ L[i][2] ] = self.P[k][ L[i-1][2] ]
else:
self.P[k][ L[i][2] ] = i
k += 1
length <<= 1 # or *=2 as you prefer
self.suf_sorted = [0] * self.n # generate the inverse:
for i, si in enumerate(self.P[-1]): # lexic. sorted suffixes
self.suf_sorted[si] = i
Let’s see how we can solve various queries with this data-structure.
Lexicographical minimal rotation of a string
Yet another solution to this classic problem. For problems involving rotations of a string s, usually we like to work with the string s+s. Let n be the size of s. Let i be the index of the lexicographically smallest suffix of s+s of length at least n. Then the n first characters of this suffix are the answer to our problem. The following implementation returns the index of this suffix.
def minimal_lexicographical_rotation(s):
""" returns i such that s[i:]+s[:i] is minimal,
for n = len(s).
Could an be solved in linear time,
but this is an easy O(n log^2 n) solution.
Uses the observation, that solution i also minimizes (s+s)[i:]
"""
A = SuffixArray(s + s)
# find index 0 <= i < len(s) with smallest rank
best = 0
for i in range(1, len(s)):
if A.P[-1][i] < A.P[-1][best]:
best = i
return best
Longest common prefix of two given suffixes
Given two suffixes identified by integers i and j, we want to compute the length q of their longest common prefix. Here we can use the pseudo-ranks stored in the matrix P. For example if $P[3][i]$ equals $P[3][j]$, then we know that the 8 first characters are the same in both suffixes. Hence by inspecting this matrix for decreasing row indices k, we can answer the query in logarithmic time. Note that visoalgo presents a linear time solution.
def longest_common_prefix(self, i, j):
"""returns the length of
the longest common prefix of s[i:] and s[j:].
complexity: O(log n), for n = len(s).
"""
if i == j:
return self.n - i # length of suffix
answer = 0
length = 1 << (len(self.P) - 1) # length is 2 ** k
for k in range(len(self.P) - 1, -1, -1):
length = 1 << k
if self.P[k][i] == self.P[k][j]: # aha, s[i:i+length] == s[j:j+length]
answer += length
i += length
j += length
if i == self.n or j == self.n: # not needed if s is appended by $
break
length >>= 1
return answer
Number of distinct substrings
Every substring is a prefix of some suffix. A suffix of length q has q prefixes. But if we would simply sum up the length of every suffix, then we might count some substrings several times. The key idea is that we assign each substring to the lexicographical smallest suffix for which it is a prefix.
Consider the lexicographical order of the suffixes. Let i, j be the indices of two successive suffixes in this order. Let q be the length of their longest common prefix. Then the strings s[j:j+r] for all r between j+q and n-j are the prefixes of the j-th suffix which are assigned to it. So instead of counting the total length of the suffixes, we amputate the length with the length of the longest common prefix with the previous suffix. This leads to the following method of complexity $O(n \log n)$. Note that we start with the length of the lexicographical first suffix.
def number_substrings(self):
answer = self.n - self.suf_sorted[0]
for i in range(1, self.n):
r = self.longest_common_prefix(self.suf_sorted[i-1], self.suf_sorted[i])
answer += self.n - self.suf_sorted[i] - r
return answer
Counting distinct substrings in $O(n^2 \log n)$
Let’s return to our problem mentionned at the beginning of the document. Given the instance size n=1000, an algorithm with complexity $O(n^2 \log n)$ would be acceptable. Hence, avoiding completely suffix arrays, we can solve the problem as follows. First create a list L with all suffixes of the given string s. Now sort L. For every sucessive pairs of suffixes in this list, compute in linear time the length of the longest commun prefix. Here the assuming a special final character in s, which does not appear elsewhere comes at hand to simplify some tests. From these lengths one can compute the answer easily.
import sys
def readint(): return int(sys.stdin.readline())
def readstr(): return sys.stdin.readline().strip()
def solve(s):
n = len(s)
L = [s[i:] + chr(0) for i in range(n)]
L.sort()
answer = n * (n + 1) // 2
for j in range(1, n):
i = 0
while L[j-1][i] == L[j][i]:
i += 1
answer -= 1
return answer
for _ in range(readint()):
print(solve(readstr()))
More problems
Here are a few problems that can be solved with the use of a suffix array.
- locate a given substring
needlein a singlehaystack. Performing binary search on the comparison onneedlewith suffixes, solves this problem in time $O(m \log n)$, where $m$ is the length ofneedle. - find the lexicographical smallest substring appearing at least k times in s. This reduces to finding the smallest index i, such that the i-th suffix and the (i+k-1)-th suffix have a common prefix of length at least k.
See this note for a large collection of problems reducing to suffix arrays.