Entrainement pendant l’année scolaire 2019-2020 à l’école centrale supélec.
Lundi 14 oct 2019, 13-15:30
Présents : 3
On a parlé des problèmes suivants:
- wordladder — Calculer par BFS les distances entre les mots du dictionnaire. Variante 1: insérer des sommets correspondant à des remplacements de lettres, par exemple W_RD. Christoph: je n’ai pas encore réussit à faire passer ma solution.
- Radar Installation — vu en TD. Réduction vers couverture d’intervalles. Soution gloutone.
- Frosting on the Cake — sommer les longueurs des colonnes et lignes de même modulo par 3
- Taxi Cab Scheme — réduction vers le problème de couverture d’un DAG par un nombre minimum de chemins: graphe biparti U = sommets correspants aux destinations des requêtes, V = .. au sources des requêtes, il y a une arête si un taxi a assez de temps de servir les deux requêtes. Couplage dans ce graphe: un arête du couplage indique que c’est le même taxi qui sert les deux requêtes. Le nombre de taxi utilisés est le nombre de requêtes moins la taille du couplage
- Mission Improbable — expliqué ici.
- Landscaping — se réduit vers un problème de coupe. Un sommet par case, ainsi qu’une source s et un puits t. Les poids sur les arêtes: si la case x est haute c(s,x)=0, c(x,t)=a, si la case est basse c(s,x)=b, c(x,t)=0. Entre deux cases adjacentes x,y il y a une arête de poids c(x,y)=b. Une coupe correspond à un solution, et la valeur de la coupe est la valeur de la solution.
- Manhattan — se réduit vers 2-SAT. Une variable booléenne par route indicant son orientation. Imaginons que pour une route on demande (x et y) ou (a et b). Ceci est équivalent à (x ou a) et (x ou b) et (y ou a) et (y ou b), qui sont des clauses 2-SAT. — résoudre une formule 2-SAT: chaque clause x ou y, génère deux implications non x => y et non y => x. Alors construire un graphe orienté avec ces arcs. Si pour une variable x il existe un chemin de x à non x et de non x à x, alors la formule n’est pas satisfiable, sinon elle l’est.
Lundi 21 oct, 12h30 – 13h30
Café CROUS du bâtiment Eiffel. On parlera des problèmes:
- Honest Rectangle — en détail, avec code
- Dragon Maze - Parcours BFS pour trouver les plus courts chemins, mettre à jour pour chaque arête le score découvert par case. Voir solution plus bas.
- Stock Charts — Définir un ordre partiel. Trouver le nombre minimum de chemins pour couvrir cet ordre. Se résoud par un couplage biparti de cardinalité maximale.
- Poker Hands — avec code
- Anagram checker - probablement une solution par backtracking. On traduit des mots en un vecteur de dimension 26, avec le nombre d’occurences de chaque lettre. On trie les lettres du dictionnaire en ordre alphabetique.
- Weird Advertisement - utiliser un arbre de segments
Lundi 28 oct, à partir de 12h
En salle ee.04
Présents : 4
- Poker Hands — avec code
- November Rain
- Stammering Aliens
- City Parc
Lundi 4 novembre
Discussions par email.
- Dungeon of Death
- Project File Dependencies
- A concrete ad_hoc — maintenir une permutation et son inverse
- ABCD — glouton avec un passage. Se débrouiller d’avoir les 4 lettres distinctes toutes les 2 positiosn.
Lundi 11 novembre
Discussions par email.
- Essayez de résoudre les problèmes de SWERC 2016. Je me souviens des solutions de certains de ces problèmes.
Lundi 18 novembre
présents: 2
Voici des suggestions pour la table des matières de votre livret de code que vous devez préparer pour la compétition:
- liste de Stanford – très structures de données
- liste de Newfoundland – très maths
- liste de Stavropol State University — compact, mais je pense que du code source complet et plus pratique
- 2 pages sur Python de Laurent Pointal — vous devriez savoir par cœur
Et voici une liste d’algorithmes traités dans notre livre.
Lundi 25 novembre
Rappels sur les différents algorithmes de plus court chemin.
Jeudi 28 novembre
- comment trouver k s-t-chemins arête disjoints de longueur totale minimale.
- étant donné un graphe G(V,E), trouver le plus petit entier y tel qu’il existe des entiers positifs x[v] pour chaque sommet v avec x[u] + x[v] > y ssi (u,v) dans E. (dernier exo de la compétition BattleDev d’aujourd’hui. Ça allait pour vous?)
Voici une liste de codes à lire: (j’ai regardé beacoup de collections de codes et retenus ce qui sont succints et complets.)
- PADS de David Eppstein – Python algorithms and data structures.
- tryalgo – notre bibliothèque avec Jill-Jênn Vie.
- 4 petits conseils en Python
- ands de nbro – Algorithms and Data Structures
Jeudi 5 décembre
12:45 - 14:15
- BattleDev - dernier problème
- test de compatibilité entre groupes sangins
- Power strings ou Period
- compter les inversions dans une permutation
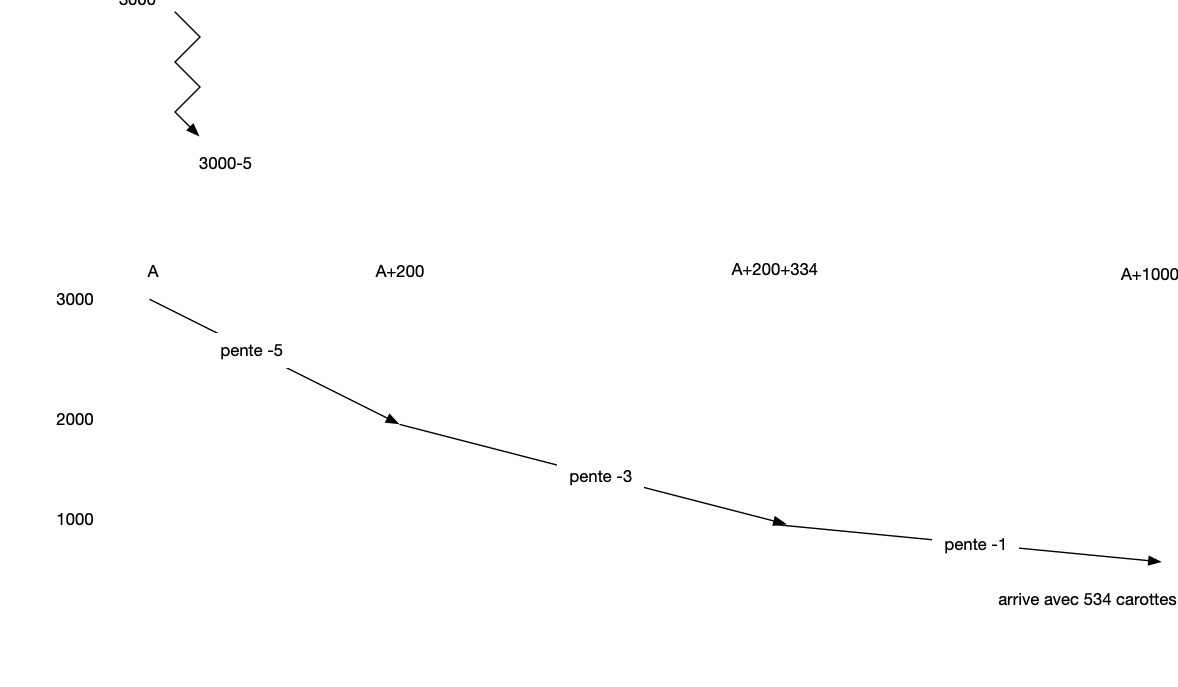
- énigme du transport de carottes. On a 3000 carottes en un point A et on veut les transporter au point B. Ces points sont à distance de 1000 mètres. Le transport peut se faire avec un âne, qui peut porter au plus 1000 carottes, mais consomme une carotte par mètre parcouru. On a la possibilité de déposer des carottes le long du chemin pour les récupérer plus tard. La solution semble vouloir optimiser la quantité transportée sur la quantité consommée. On a une solution, mais pas encore la preuve d’optimalité.
{kind=link}
Exercices à discuter lors d’une prochaine rencontre:
- spoj:NEXTPERM — c’est une fonction toute faite déjà dans la STL de C++
- poj:Traffic Jam
- uva:Corner the Queen
- Pipelines
Mardi 17 décembre
- Palindrome in a Tree – par les arbres de Fenwick
Ingrédients:
- Associer à chaque noeud avec la lettre c, l’entier 1«(ord(c)-ord(‘a’)), codant sur 26 bits le vecteur caractéristique de la lettre c. Pour un sous-arbre donnée, faire le ou exclusif de ces nombres. Si le résultat est 0 ou une puissance de 2, alors effecivement chaque lettre dans le sous-arbre apparait un nombre paire de fois, sauf peut-être une seule lettre qui apparaît un nombre impair de fois. C’est exactement ce qu’il faut pour former un palindrome.
-
Calculer cette somme est trop couteux, alors l’idée est d’attribuer des identifiants aux noeuds de l’arbre en plus des numéros données, en prenant l’ordre de visite par un parcours en profondeur. Ainsi les noeuds d’un sous-arbre forment un intervalle parmi les indices. Désormais on peut utiliser un arbre de Fenwick, en utilisant l’opérateur de ou exclusif ^ plutôt que l’addition habituelle.
- La complexité sera en O(n + m log n).
Lundi 6 janvier 14 - 15
Samedi 11 janvier 14 - 17 Starbucks les Halles
Mardi 14 janvier 12h30 - 13h30
- le test de Freivalds — Propriété clé. Si on choisit un nombre uniformément au hasard dans $Z_p$, alors il sera égal à une valeur fixée avec probabilité $1/p$. Considérons la matrice $M = AB-C$, et une ligne $i$ non nulle dans $M$. Soit $j$ la dernière colonne avec $M_{ij}$ non nul. Alors pour $x_1,\ldots,x_{j-1}$ fixé, avec probabilité $1/p$ la valeur de $x_j$ sera choisi tel que $M x$ est nul dans l’entrée à l’indice $i$. Donc il semble que la probabilité d’un faux positif soit $1/p^\ell$ où $\ell$ est le nombre de lignes non nulles dans $M$.
- Algorithme de Rabin-Karp – ideal pour trouver en temps linéaire espéré si une grande chaîne x contient une des chaînes $y_1,\ldots,y_k$ (qui doivent avoir la même longueur).
Samedi 18 janvier 10 - 17 LIP6 à Jussieu
- Le théorème de Sprague-Grundy
- Résoudre un système d’équation linéaire par triangulation de Gauss-Jordan. Ars Longa
- Construire un arbre syntaxique
Weekend du 25 janvier
Pas de médaille cette année, mais on a fait une bonne performance pendant la séance d’entrainement, et aussi pendants d’autres compétitions qui ont eu lieu pendant l’année (par exemple, on a atteint le rang 7 sur 5334 pendant la compétition battledev.)
Honest Rectangle
Idea
Conceptually, we fill a matrix M with rows indexed by h and columns indexed by w. M[x,y] contains x * y. Avery gets a value from this matrix, while Pat gets an anti-diagonal. We will erase entries corresponding to (w,h) pairs which are not compatible with the conversation. The surviving entries are the solution.
“Avery: I don’t know what w and h are.” means that we erase all entries which are unique,
“Pat: I knew that.” means we erase all anti-diagonals where we erased individual entries.
“Avery: Now I know what they are.” means we erase all entries which are not unique among the remaining entries.
“Pat: I now know too.” means we erase all anti-diagonals which do not contain exactly one entry.
Implementation
We don’t really store the matrix M, but maintain an bookkeeping array, namely:
count_prod[y] is the number of non-deleted pairs (w,h) such that w * h = y.
The function count_unique uses this table to determine for each anti-diagonal how many entries it has which are unique in M.
Complexity
in the order of 5 * U^2, which is ok for U = 1000
Code
import sys, string
def readint(): return int(sys.stdin.readline())
def readstr(): return sys.stdin.readline().strip()
L = readint()
U = readint()
possibilities = [(w, h) for w in range(L, U + 1) for h in range(w, U + 1)]
count_prod = [0] * (U * U + 1)
"""
returns a table unique, such that unique[y] is the number of pairs (w,h)
with w + h == y and count_prod[w * h] == 1.
"""
def count_unique():
unique = [0] * (U + U + 1)
for w, h in possibilities:
if count_prod[w * h] == 1:
unique[w + h] += 1
return unique
for w, h in possibilities: # add all possible pairs
count_prod[w * h] += 1
unique1 = count_unique()
for w, h in possibilities: # remove pairs after Pat says: I knew that.
if unique1[w + h] > 0:
count_prod[w * h] -= 1
unique2 = count_unique()
for w, h in possibilities: # filter surviving pairs
if unique1[w + h] == 0 and unique2[w + h] == 1 and count_prod[w * h] == 1:
print(w, h)
wordladder — Help Needed, not accepted by SPOJ
Compute distances in a Hamming distance defined graph on given words.
complexity
n * k * 27 * 2 + n * n * k
for n the number of words and k their length. which is about 8 million. should be ok.
General approach
Use BFS to compute the distances from the source word. Do the same for the target word. Then if target is reachable from source, we have already one candidate solution distance. Next we iterate over all words u reachable from source and all words v reachable from target with Hamming distance 2 between u and v. We compute the lexicographical smallest word in between u and v. This gives us another candidate solution. We keep the best candidate solution.
A solution is a pair (distance, added_word), where it comes in handy that “0” is smaller as all given words.
Improvements
For the BFS we could iterate over all 27 * 8 possible neighbors of a word and check if they belong to the dictionary. But we could also precompute a list of words for every replacement. For example replace[“AB.C”] would contain all words from the dictionary that match the regular expression “AB.C”. Doing this the complexity will reduce to n * k * 2 * a, where a is the average number of words which differ at the same position, which likely to be a small constant, much less than 27. The second part will have complexity n * k ** 2 * b, where b is the average number of words which differ in exactly two positions, also expected to be much smaller than 27 ** 2.
Experiments show that that we gain a factor of 5 at least in the running time.
Code en Python (WRONG ANSWER)
import sys, string
from collections import defaultdict
def readint(): return int(sys.stdin.readline())
def readstr(): return sys.stdin.readline().strip()
n = readint()
tout = [readstr() for _ in range(n)]
dico = set(tout)
Pos = range(len(tout[0]))
def all_remove1(w):
for p in Pos:
yield w[:p] + "_" + w[p+1:]
def all_remove2(w):
for q in Pos:
for p in range(q):
yield w[:p] + "_" + w[p + 1: q] + "_" + w[q + 1:]
all_replace1 = defaultdict(lambda: set())
for w in tout:
for remove1 in all_remove1(w):
all_replace1[remove1].add(w)
all_replace2 = defaultdict(lambda: set())
for w in tout:
for remove2 in all_remove2(w):
all_replace2[remove2].add(w)
def distances(start):
Q = [start]
d = {start : 0}
while Q:
w = Q.pop() # BFS
for remove in all_remove1(w):
for replace in all_replace1[remove]:
if replace in dico and replace not in d:
d[replace] = d[w] + 1
Q.append(replace)
return d
def two_steps(u, v):
"""If Hamming distance is 2, returns a string in between at Hamming distance
1 from u and from v and minimal in lexicographical order.
Otherwise returns None.
"""
# positions where u and v differ
p = [i for i in Pos if u[i] != v[i]]
if len(p) != 2:
return None
i, j = p
if u[i] < v[i]:
return u[:j] + v[j:]
else:
return v[:j] + u[j:]
left = distances(tout[0])
right = distances(tout[1])
# print(left, right)
if tout[1] in left:
best = (left[tout[1]], "0")
else:
best = (float('inf'), "0") # par défault si pas de solution
for u in left:
for remove in all_remove2(u):
for v in all_replace2[remove]:
if v in right:
w = two_steps(u, v)
if w is not None and w not in dico:
alternative = (left[u] + 2 + right[v], w)
if alternative < best:
best = alternative
if best[0] != float('inf'):
print(best[1])
print(best[0])
else:
print(0)
print(-1)
Code en C++ (ACCEPTED)
Ici on utilise une approche légèrement différente. La fonction distances calcule par BFS les distances à partir d’un mot source dans le graphe décrit par les mots donnés et la distance de Hamming 1. Puis la fonction boundary calcule pour un dictionaire dist donné, tous les mots qu’on peut obtenir à partir des clés w de dist en changeant une lettre, et on y associant la distance dist[w] + 1.
La complexité de cette procédure est de l’ordre de 4 * 27 * 8 * 1000 avec une grande constante due au test d’appartenances à des dictionaires. Mais ça passe.
#include <iostream>
#include <map>
#include <string>
#include <queue>
#include <set>
#include <climits>
using namespace std;
string tout[1001];
set<string> dico;
map<string,int> distances(string start) {
map<string, int> dist;
dist[start] = 0;
queue<string> Q;
Q.push(start);
while (! Q.empty()) {
string u = Q.front();
Q.pop();
for (int i = 0; i < u.size(); ++i)
for (char x = 'A'; x <= 'Z'; ++x) {
string v = u.substr(0, i) + x + u.substr(i + 1);
if (dico.count(v) && dist.count(v) == 0) {
dist[v] = dist[u] + 1;
Q.push(v);
}
}
}
return dist;
}
map<string,int> boundary(const map<string,int> & dist) {
map<string, int> border;
for(pair<string, int> p: dist) {
string u = p.first;
for (int i = 0; i < u.size(); ++i)
for (char x = 'A'; x <= 'Z'; ++x) {
string v = u.substr(0, i) + x + u.substr(i + 1);
int d = p.second + 1;
if (border.count(v) == 0 || d < border[v])
border[v] = d;
}
}
return border;
}
int main() {
int n, k;
cin >> n;
for (int i = 0; i < n; ++i)
cin >> tout[i];
dico.insert(tout, tout + n);
string source = tout[0];
string target = tout[1];
k = source.size();
map<string,int> left = distances(source);
map<string,int> right = distances(target);
pair<int,string> best(INT_MAX, "0");
if (left.count(tout[1]))
best.first = left[tout[1]];
map<string,int> left_border = boundary(left);
map<string,int> right_border = boundary(right);
for (pair<string, int> p : left_border) {
string u = p.first;
if (right_border.count(u)) {
pair<int, string> alternative(p.second + right_border[u], u);
if (alternative < best)
best = alternative;
}
}
if (best.first == INT_MAX)
cout << "0" << endl << -1 << endl;
else
cout << best.second << endl << best.first << endl;
return 0;
}
Dragon Maze
""" Dragon Maze
http://code.google.com/codejam/contest/2929486/dashboard#s=p3
Explore grid using BFS in order to discover shortest paths. Update the
maximum power along the forward edges in the BFS level graph.
complexity: linear in grid size
"""
from collections import deque
def readint(): return int(raw_input())
def readarray(f): return map(f, raw_input().split())
for test in range(readint()):
N, M = readarray(int)
enter_x, enter_y, exit_x, exit_y = readarray(int)
grid = [readarray(int) for _ in range(N)]
power = [[-1 for j in range(M)] for i in range(N)]
level = [[None for j in range(M)] for i in range(N)] # mark vertices inserted in queue
Q = deque()
power[enter_x][enter_y] = grid[enter_x][enter_y]
level[enter_x][enter_y] = 0
Q.append( (enter_x, enter_y) ) # start from the enter cell
while Q:
x, y = Q.popleft() # loop over all 4 neighbors
for x1, y1 in [(x - 1, y), (x + 1, y), (x, y - 1), (x, y + 1)]:
if 0 <= x1 < N and 0<= y1 < M: # if in bounds of grid
if grid[x1][y1] == -1:
continue # ignore dangerous cells
if level[x1][y1] is None: # level discovered for this cell
level[x1][y1] = level[x][y] + 1
Q.append( (x1,y1) )
if level[x1][y1] == level[x][y] + 1: # if arc in level graph
alt = power[x][y] + grid[x1][y1]
if power[x1][y1] < alt:
power[x1][y1] = alt # update reachable power value
sol = power[exit_x][exit_y]
if sol == -1:
print("Case #%i: Mission Impossible." % (test + 1))
else:
print("Case #%i: %i" % (test + 1, sol))
ABCD
glouton avec une seule lecture.
Vous avez bien trouvé. L’idée est de grouper les deux chaînes en blocs de 2x2 caractères. Maintenant il y a plusieurs manières de procéder. Par exemple:
Se débrouiller pour que dans les fenêtes de forme [2i,2i+1] on trouve toutes les 4 lettres. Donc les deux lettres du haut définissent ceux du bas, qui pourraient à priori être dans deux ordres possibles, mais la lettre précédente du bas détermine l’ordre. Ceci est stocké dans le dictionnaire T par un précalcul.
| x1 | x2 |
b | ? | ? |
T[b, x1, x2] est le couple de lettres qu’il faut placer à la place des ‘?’.
complexité
O(N)
Mauvais Algorithme
de gauche à droite, placer parmi les lettres possible celle qui a le plus grand nombre d’occurence restants (et lexicographiquement la plus petite en cas d’égalité)
CONTRE EXEMPLE
C A B D
A B C ?
from sys import *
def readint(): return int(stdin.readline())
def readstr(): return stdin.readline().strip()
T = {}
for b in "ABCD-":
for x1 in "ABCD":
for x2 in "ABCD":
if x1 != x2:
s = ""
for y in "ABCD":
if y!=x1 and y!=x2:
s += y
if b == s[0]:
s = s[::-1]
T[b, x1, x2] = s
N = readint()
if N > 0:
top = readstr()
b = '-'
for i in range(N):
bottom = T[b, top[2 * i], top[2 * i + 1]]
print(bottom, end='')
b = bottom[-1]
print()