Deep Reinforcement Learning
Stable Baselines rely on TF 1.x but Stable Baselines v3 rely on PyTorch.
- Breakout v4 and v5 are in the Atari Learning Environment (
ale-py) - There exists a MinAtar environment that is 10x faster to train than the original Breakout (mini Atari). I fixed it in a fork so that Stable Baselines v3 can be used.
- DQN of stable-baselines
- Actor-Critic A2C of stable-baselines
- Actor-Critic is very sensitive to hyper-parameter
Benchmarks
- Best models on Breakout-v5 using CleanRL thanks to this Reddit post
- Extra features of DQN, notably Rainbow
- Yet another benchmark
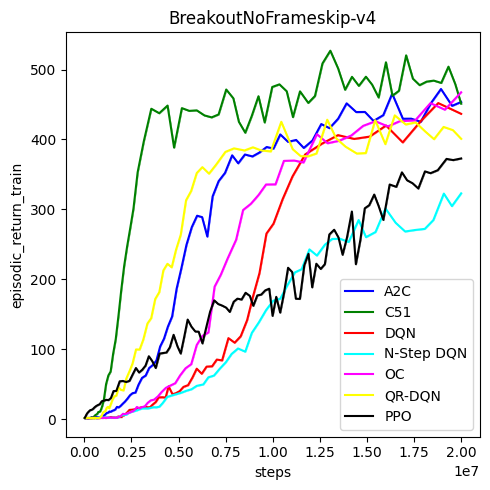
Best model from CleanRL:
ppo_atari_envpool.py --exp-name a2c --update-epochs 1 --num-minibatches 1 --norm-adv False --num-envs 64 --clip-vloss False --vf-coef 0.25 --anneal-lr False --num-steps 5 --track.
Fun fact
- Running on my CPU was faster than Colab GPU (for the MinAtar environment), possibly because the data was not high dimensional and the network was not very deep