Trier un tableau en un nombre minimal d'étapes d'insertion
Le problème
Une permutation d’un intervalle d’entiers de 1 à n est un arrangement des entiers de cet intervalle. C’est donc toujours une liste de taille n, où chaque entier de l’intervalle apparaît une et une seule fois.
Considérons deux permutations de l’intervalle d’entiers de 1 à 4 inclus :
> lst1 = [4, 1, 2, 3]
> lst2 = [3, 4, 2, 1]On veut calculer une suite de mouvements de taille minimale qui permet de passer d’une permutation à l’autre. Le seul mouvement autorisé est l’insertion, c’est-à-dire qu’étant donné un indice de départ et un indice d’arrivée dans la liste, on supprime l’élément à la position de départ, et on le place à la position d’arrivée (le même mouvement que l’on fait dans le tri par sélection, ou lorsque l’on place une carte dans sa main), en décalant vers la droite tous les éléments à partir de la position d’arrivée. Par exemple, dans la première liste (en commençant à numéroter à zéro), si notre mouvement à faire est [1, 0], alors notre liste à la fin du mouvement sera :
> lst1 = insert_before(lst1, [1, 0])
> lst1
[1, 4, 2, 3]Par exemple, on peut implémenter insert_before in Python de la façon suivante :
def insert_before(ls, move):
[pos, new_pos] = move
n = len(ls)
new_ls = [0]*n
# On place l'élément à sa nouvelle position
new_ls[new_pos] = ls[pos]
other_elements = []
for i in range(n):
if (not (i == pos)):
other_elements = [ls[i]] + other_elements
# On ajoute les autres éléments
for i in range(n):
if (new_ls[i] == 0):
new_ls[i] = other_elements.pop()
return new_lsPar exemple, on passe de la première liste à la deuxième en deux mouvements : [1, 3] puis [0, 1] (sur la liste où on a déjà appliqué le premier mouvement).
//indices [0, 1, 2, 3]
> lst1
[4, 1, 2, 3]
> lst1 = insert_before(lst1, [1, 3])
> lst1
[4, 2, 3, 1]
> lst1 = insert_before(lst1, [2, 0])
> lst1
[3, 4, 2, 1]
# Pour tout i, i vérifie l'égalité entre les éléments
# à la position i respectivement dans ls1 et ls2
> all([ls1[i] == ls2[i] for i in range(len(lst2))])
TrueFormalisation
C’est un problème de tri de tableau (placer tous les éléments à la bonne position en fonction de leur valeur), avec un ordre sur les entiers qui est donné par la liste d’arrivée. Si cette dernière est [1, 2, 3, …, n-1, n], alors c’est l’ordre naturel sur les entiers tel qu’on le connaît. Par souci de clarté dans la suite, on va se placer dans ce dernier cas, quitte à remplacer l’ordre naturel sur les entiers “<” par la fonction “compare” suivante :
# Comparer les positions des deux éléments e1 et e2
# dans la liste lst2
def compare(e1, e2, lst2):
pos1 = lst2.index(e1)
pos2 = lst2.index(e2)
return(pos1 < pos2)La difficulté majeure consiste à calculer explicitement une suite de mouvements de taille minimale pour passer d’une liste à l’autre. Commencer par chercher comment déterminer le nombre minimal de mouvements mène à la solution suivante.
Une solution
Trouver le nombre minimal de mouvements nécessaires
Une sous-séquence d’une liste est une suite non vide d’éléments de la liste, dans l’ordre dans lequel ils apparaissent dans la liste. Par exemple, [4, 2, 3], [1], [2, 3] et [4, 1, 2, 3] sont des sous-séquences de la liste [4, 1, 2, 3]. Une sous-séquence est dite croissante si les éléments présent dans cette sous-séquence sont classés dans l’ordre croissant de leurs valeurs. Par exemple, parmi les séquences citées auparavant, seules [1] et [2, 3] sont croissantes (pour l’ordre naturel des entiers).
Le problème de la plus longue sous-séquence croissante consiste à trouver une sous-séquence croissante de taille maximale. Attention, il peut y en avoir plusieurs, par exemple [2, 3], [1, 4], [2, 4] et [1, 3] dans la liste [2, 1, 4, 3].
Le lemme suivant permet de comprendre pourquoi résoudre ce problème subsidiaire nous sera utile :
Lemme Le nombre minimal de mouvements nécessaires pour trier un tableau de taille n est égal à n-s, où s est la taille des plus longues sous-séquences croissantes.
Démonstration Un mouvement dans le tableau ne pourra augmenter la taille des plus longues sous-séquences croissantes qu’au maximum de 1 élément. Si la taille des plus longues sous-séquences croissantes s est égale à la taille du tableau entier n, alors cela signifie que le tableau est trié. Donc il est nécessaire d’effectuer au moins n-s mouvements. La partie “il suffit d’effectuer n-s mouvements” sera prouvé par l’algorithme que l’on exhibera ci-dessous.
Calculer une plus longue sous-séquence croissante
On utilise de la programmation dynamique ici (voir l’article sur le rendu de monnaie pour plus de détails sur ce paradigme). Pour une implémentation en Python de cette méthode en temps quasi linéaire en la taille des tableaux d’entrée, voir cette page. La page Wikipédia (en français) explique très clairement la démarche suivie. Pour l’adapter au cas où la liste d’arrivée n’est pas triée selon l’ordre naturel des entiers, il suffit de remplacer toutes les comparaisons par la fonction “compare” que l’on a définie plus tôt.
Obtenir les mouvements nécessaires à partir d’une plus longue sous-séquence croissante
Une fois que l’on a calculé une plus longue sous-séquence croissante (PLSC), on va intuitivement chercher à transformer cette sous-séquence (en conservant sa propriété de croissante et de maximalité) en lui “ajoutant” un à un des éléments à la bonne position (et en modifiant la liste de départ en parallèle) jusqu’à ce que la taille de cette sous-séquence soit égale à la taille des deux listes d’arrivée et de départ. Par exemple, pour les deux listes suivantes :
> lst1 = [4, 1, 2, 3]
> lst2 = [1, 2, 3, 4]Une (la seule) plus longue sous-séquence pour lst1 est [1, 2, 3]. Or, comme cette sous-séquence est ordonnée selon l’ordre donné par la liste d’arrivée lst2, c’est aussi une sous-séquence croissante pour lst2 (mais pas forcément de taille maximale). Une fois que cette sous-séquence sera aussi longue que lst2, alors cette sous-séquence croissante sera égale à lst1 et à lst2, donc lst1 sera égale à lst2.
Les trois premiers éléments de lst2 sont bien placés dans la PLSC, donc leur position n’est pas modifiée. En revanche, l’élément d’indice 3 (égal à 4) n’apparaît pas dans la PLSC. Puisqu’aucun élément présent dans la PLSC n’existe après l’indice 3 dans lst2, il faut donc placer 4 après les trois éléments de la PLSC [1, 2, 3] dans lst1 : si un élément présent dans la PLSC existait après l’indice 3, alors il faudrait placer 4 juste avant cet élément (autrement dit, insérer 4 à la position de cet élément). Le mouvement d’insertion à effectuer est donc [0, 3]. On modifie la PLSC : [1, 2, 3, 4] et lst1 = [1, 2, 3, 4]. On obtient lst1 = lst2 à la suite de ce mouvement, et n-s = 4-3 = 1, ce qui est cohérent.
Cet algorithme termine, puisqu’on inspecte un à un, dans l’ordre, les éléments de la liste lst2. Mais est-ce que cet algorithme est correct ?
Correction Pour cela, il faut montrer qu’à tout étape de l’algorithme, on préserve la propriété de croissance, de maximalité, et de sous-séquence de la liste de départ de la PLSC (que l’on notera subseq pour éviter les confusions).
Démonstration A l’étape numéro i (où i est compris entre 0 et n-1) :
- soit ni subseq ni la liste de départ obtenue après i-1 étapes ne sont modifiées (si l’élément inspecté appartient déjà à subseq/la PLSC), donc la propriété à démontrer est vérifiée;
-
soit, dans le cas contraire, soit c l’élément courant:
-
S’il existe au moins un élément situé après c dans lst2, qui apparaît également dans subseq, notons x l’élément qui vérifie ces propriétés et qui est le plus proche de c dans lst2. Ajoutons c juste avant x dans subseq, et insérons c à la position de x dans lst1 (*). Alors c est situé juste avant x dans subseq et dans lst1 à présent, donc subseq reste une sous-séquence de lst1. subseq reste aussi croissante, car c < x (selon l’ordre donné par la liste ls2), et s’il existait un élément situé avant x dans subseq plus grand que c, cela contredirait le fait que x soit l’élément dans subseq le plus proche de c.
- Sinon, ajoutons c à la fin de subseq, et insérons c à la fin de la liste. subseq reste une sous-séquence de lst1. c est le plus grand élément de subseq (sinon il existerait un élément situé après c dans lst2, qui apparaît également dans la PLSC de lst1 à l’étape i-1, par croissance de la PLSC). Comme le reste des éléments de subseq est ordonné dans subseq, et plus petit que c, alors subseq est croissante.
De plus, une insertion ne peut augmenter la taille de la PLSC qu’au maximum de 1, or subseq est une sous-séquence croissante de taille s+1, où s est la taille de la PLSC pour lst1 à l’étape i-1, donc subseq est maximale. Donc pour tout i, subseq reste une PLSC de la liste courante lst1 à l’étape i.
De plus, on ne modifie lst1 (autrement dit, on n’effectue un mouvement d’insertion) que lorsqu’on ajoute un élément à subseq, jusqu’à ce que subseq soit de taille n. Donc on n’effectue que n-s mouvements, où s est la taille de la PLSC à l’étape initiale.
Une implémentation en Python de l’algorithme est disponible ci-dessous :
# ls1 est la liste de départ
# ls2 est la liste d'arrivée
# subseq est une plus longue sous-séquence de ls1
# (pour l'ordre donné par ls2)
def moves(ls1, ls2, subseq):
moves = []
n = len(ls2)
ls = ls1
for i in range(n):
# Elément à éventuellement déplacer
current = ls2[i]
# Si l'élément est déjà bien placé
# dans la PLSC, alors il ne sera pas déplacé
# et on inspecte le prochain élément
if (current in subseq):
continue
else:
# Sinon, on va chercher où se trouve
# cet élément relativement aux entiers
# présents dans la PLSC
# On cherche donc le prochain élément de la liste
# qui apparaît dans la PLSC
exists_next = False
index_current = ls.index(current)
for j in range(i+1, n):
next = ls2[j]
if (next in subseq):
# next est le prochain élément de la liste
# apparaissant dans la PLSC
index_next = ls.index(next)
# (*)
if (index_current < index_next):
index_next -= 1
# On va insérer l'élément courant
# avant next
moves.append([index_current, index_next])
exists_next = True
break
if (not exists_next):
moves.append([index_current, (n-1)])
# On applique le mouvement d'insertion à la liste courante
ls = insert_before(ls, moves[-1])
return movesPour aller plus loin
Trois hypothèses sont implicitement requises dans cet algorithme : que les listes d’entrée soient de la même taille, et que tous les éléments apparaissent dans les deux listes, une seule et unique fois.
Si le problème autorise en plus les mouvements de suppression et d’ajout d’un élément à une liste, on peut relâcher les deux premières hypothèses, et l’algorithme peut trouver les mouvements d’insertion (dans le sens insertion_before) pour les listes réduites à leurs éléments communs.
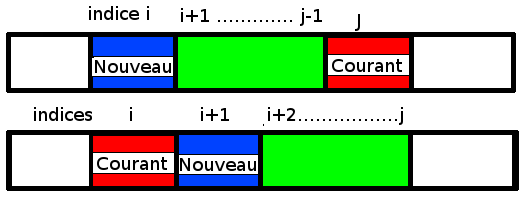
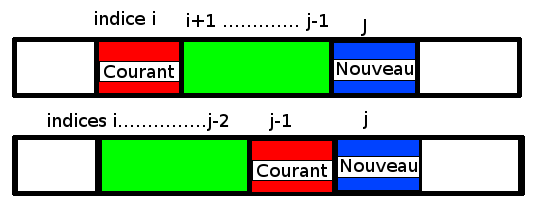
(*) Il faut tenir compte du décalage pour les éléments situés après l’indice d’arrivée dans le cas où l’indice de départ se situe avant l’indice d’arrivée :
Dans ce cas-là, l’insertion de l’élément courant se fait à j-1 (et non à j).
Dans le cas où l’indice de départ se situe après l’indice d’arrivée, l’insertion de l’élément courant se fait à i :